MDIA is a clinical reasoning system built by TietAI. On HealthBench Professional, OpenAI's most rigorous medical benchmark drawn from real clinician conversations, MDIA scores 0.627, surpassing OpenAI's own ChatGPT for Clinicians (0.590) and the physician-written baseline (0.437), using OpenAI's own grader.
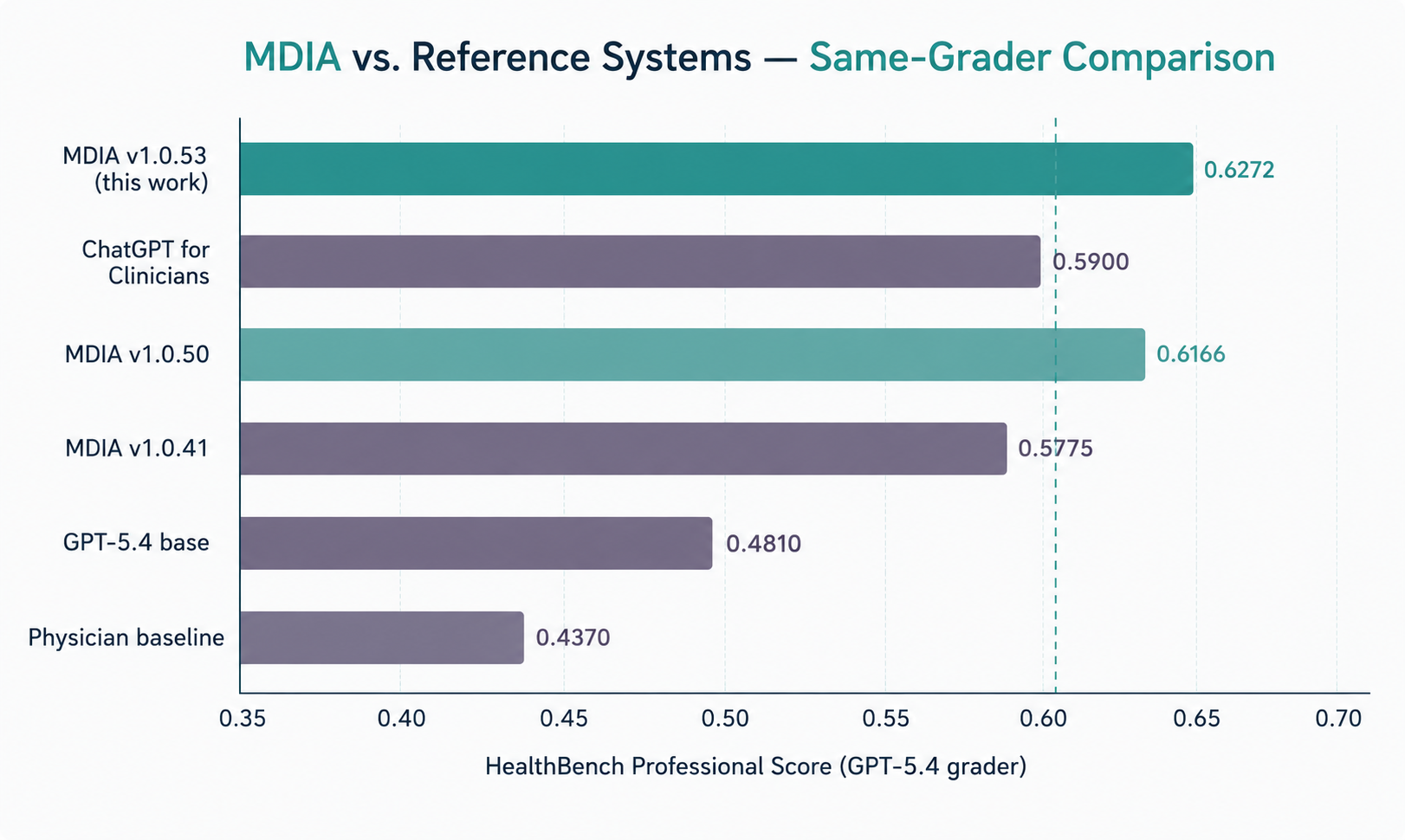
Overall comparison. Each bar shows the rubric score on HealthBench Professional (n = 525) under OpenAI's own GPT-5.4 grader. MDIA v1.0.53 reaches 0.627, 3.7 points above ChatGPT for Clinicians and 19 points above the physician-written baseline.
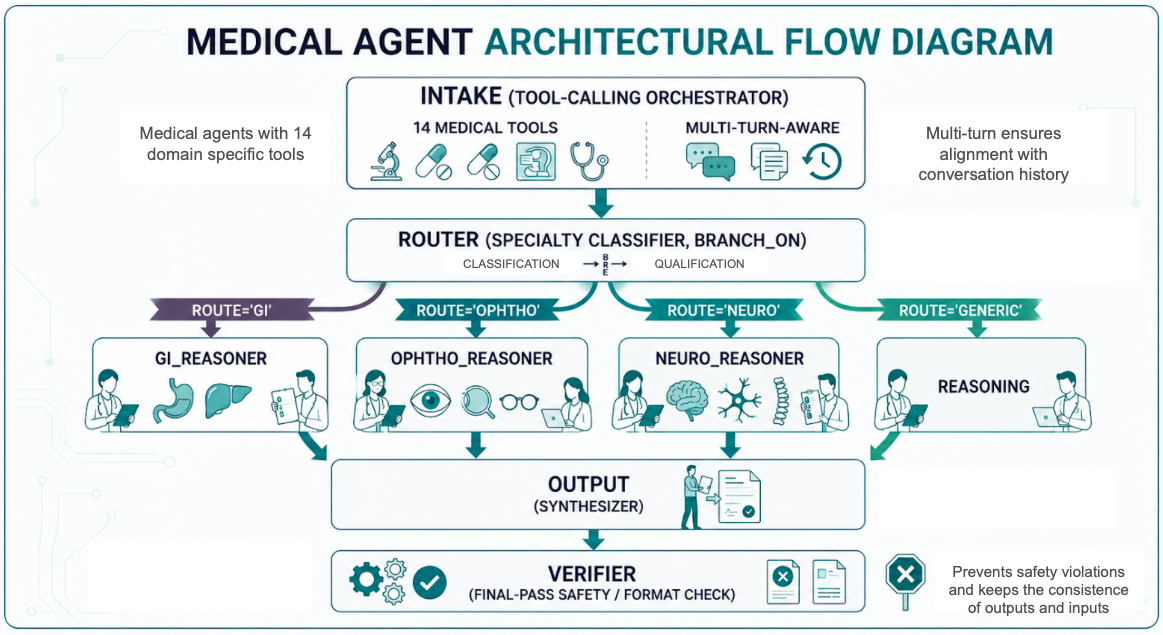
Most medical chatbots are a single large language model with a fancy prompt. MDIA is different. It is a coordinated graph of seven agents, each with its own role and tools, that work together to read a patient's question, look things up in trusted medical sources, decide which specialist should answer, write a response, and double-check it for safety.
We built MDIA on TietAI's Hydra Platform, an internal agent-orchestration engine, using off-the-shelf Google Gemini models as the underlying reasoners. No fine-tuning, no proprietary medical data, no special model access. All of the performance gains come from the way the agents are wired together and the engineering work behind them.
HealthBench Professional contains 525 real clinical conversations spanning 21 specialties, from gastroenterology to neurology to oncology, graded by a detailed rubric written by physicians. Every system in the chart below was run on the same 525 cases and graded by the same OpenAI grader.
| System | Score |
|---|---|
| MDIA v1.0.53 (TietAI - this work) | 0.627 |
| ChatGPT for Clinicians (OpenAI) | 0.590 |
| GPT-5.4 single-agent baseline | 0.481 |
| Claude Opus 4.7 | 0.470 |
| GPT-5 | 0.462 |
| GPT-5.2 | 0.459 |
| Gemini 3.1 Pro | 0.438 |
| Physician-written baseline | 0.437 |
| Grok 4.20 | 0.361 |
All scores on the full HealthBench Professional benchmark (n = 525), graded by OpenAI's GPT-5.4-2026-03-05. Reference scores from OpenAI, 2026.
When a question arrives, say a clinician asking about a 38-week pregnant patient on ACE inhibitors, MDIA does not answer right away. It walks the question through a pipeline of small, specialised agents, each focused on one job.
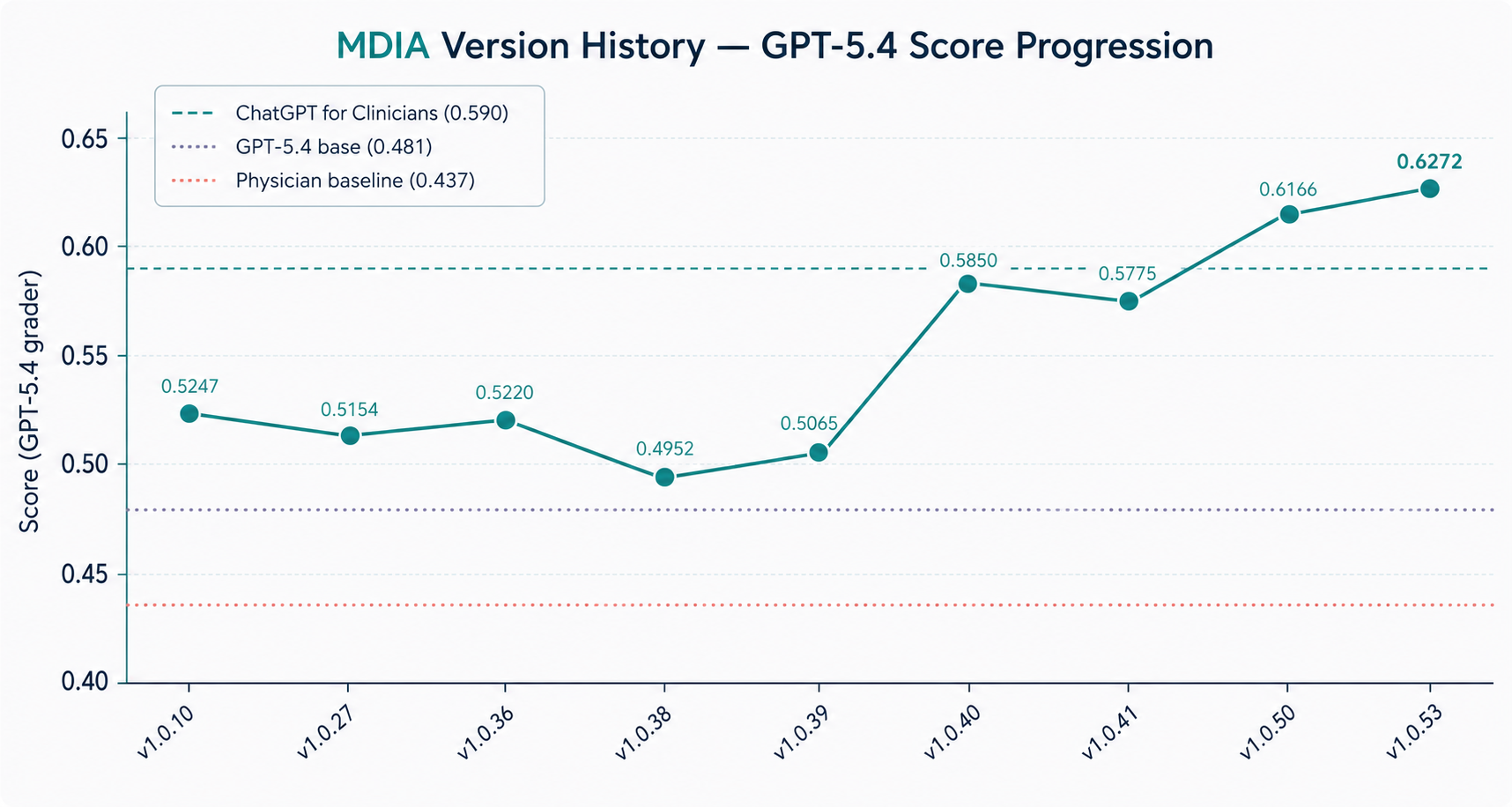
The popular narrative on AI progress is "bigger model, better answers." Our results tell a different story for the clinical setting: most of the lift came from how the system was assembled, not from a larger or fine-tuned base model. A small team with a well-engineered agent graph can outperform a domain-specific model released by a major lab.
But there is an important caveat: the score depends a lot on who is doing the grading. When we re-graded the same MDIA responses with Google's Gemini 2.5 Pro instead of OpenAI's GPT-5.4, the score jumped to 0.658. That is a 3-point swing on the same answers. Robust evaluation needs multiple independent graders, not a single judge, especially when the company writing the benchmark is also the company building one of the models being compared.
No. Benchmark performance is a technical indicator, not regulatory approval. MDIA has not been validated in prospective clinical trials and should not be used for direct patient care without further evaluation, clinician oversight, and the relevant regulatory clearances.
No. MDIA uses off-the-shelf Google Gemini models. The performance comes from the agent architecture, the medical tools the agents can call, and engineering work on the underlying platform, not from training data.
We have published the per-sample grader transcripts and evaluation framework in the TietAI Evals Public repository. The full graph definitions, prompts and engine fixes are available to other research teams on request.
Bootstrap resampling gives sigma approximately 0.023, so a 3.7-point gap is directionally consistent but not statistically decisive at p < 0.05. OpenAI does not publish confidence intervals for ChatGPT for Clinicians, which makes a formal significance test impossible. We treat the lead as meaningful but not as a knockout result; the more interesting story is the gap to the GPT-5.4 single-agent baseline (+14.6 pp).
Four things: connecting MDIA to a curated guideline retrieval system (RAG) to plug the remaining knowledge gaps; testing Claude as the specialist reasoner; building an automated harness that prevents regressions during prompt iteration; and a cross-system regrade if OpenAI publishes per-sample outputs for ChatGPT for Clinicians.