Clinical coding is a fine-grained retrieval problem: short clinical mentions must map to the right ICD-10/CIE-10 code despite subtle differences in severity, anatomy, temporality, and etiology. We show that compact task-specific retrievers, trained with LLM-generated supervision and clinically meaningful hard negatives, can outperform public embedding models and BM25 on CodiESP and DISTEMIST.
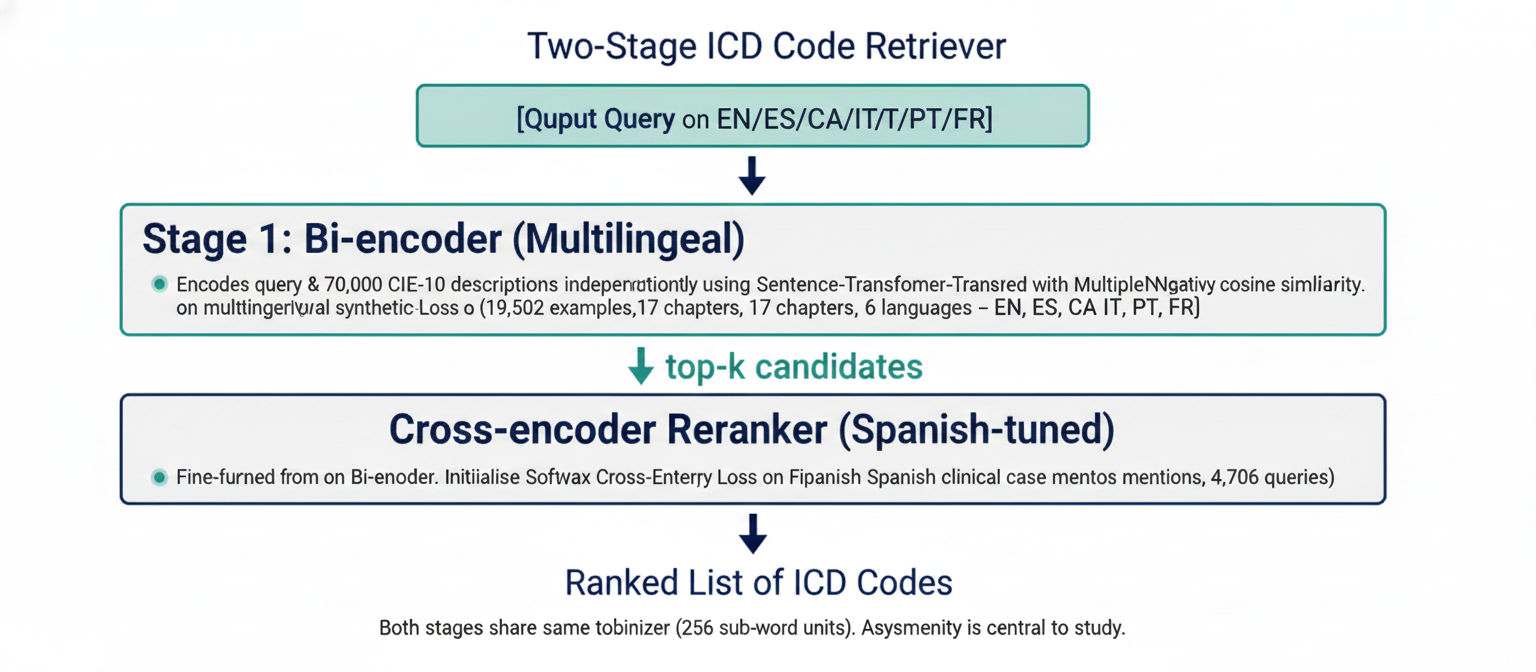
Two-stage ICD retrieval. A multilingual bi-encoder retrieves candidate CIE-10 codes, then a Spanish-tuned cross-encoder reranks the shortlist to recover clinically relevant distinctions such as laterality, severity, etiology, and episode type.
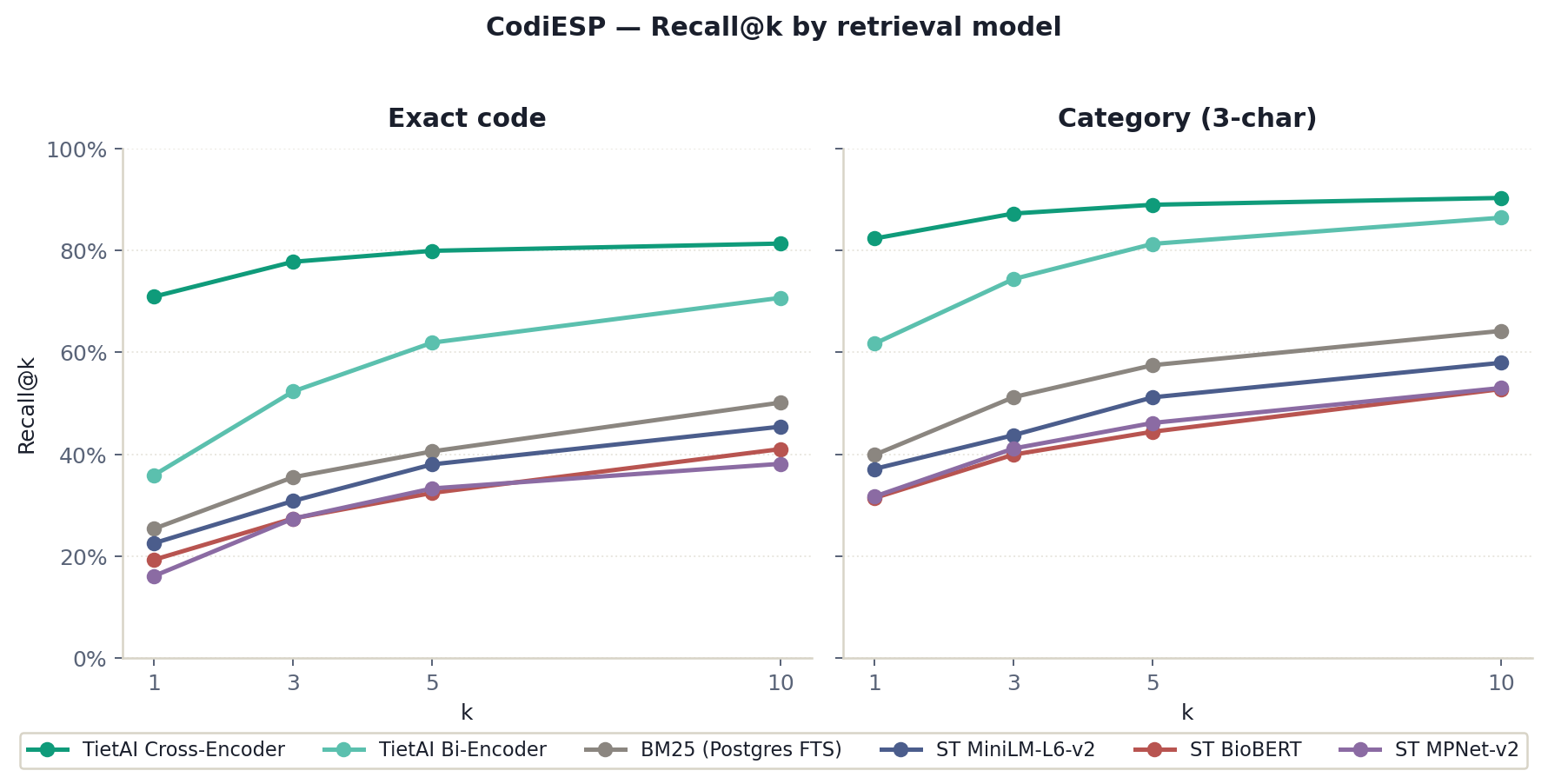
Sentence embeddings work well for broad semantic search, but ICD coding is not broad semantic search. The model must map short clinical mentions to a controlled vocabulary where neighboring codes often differ by a qualifier: anatomical site, laterality, severity, encounter type, or etiology.
The paper asks whether high-quality synthetic supervision can close that gap for Spanish clinical coding. We use a frontier LLM to generate multilingual examples grounded in the ICD-10 hierarchy, fine-tune a Spanish biomedical bi-encoder, then train a cross-encoder reranker on listwise groups with clinically plausible hard negatives.
The retriever uses a standard but carefully aligned two-stage architecture. Stage 1 encodes each query and CIE-10 description independently and ranks by cosine similarity. Stage 2 jointly reads each query-code pair and reorders the top candidates with a listwise objective.
The training data was not treated as raw synthetic output. We curated the generated examples through rule-based validation, semantic deduplication, language consistency checks, and manual spot inspection before using them to build the bi-encoder and reranking classifiers. That curation step is central to the paper: the goal is not simply to make more data, but to create examples and hard negatives that reflect the clinical distinctions encoded in ICD-10/CIE-10.
| Strategy | Role in the study |
|---|---|
| TietAI Cross-Encoder | Reranks the bi-encoder shortlist and optimizes exact-code ordering. |
| TietAI Bi-Encoder | Spanish biomedical dense retrieval backbone fine-tuned on synthetic supervision. |
| BM25 (Postgres FTS) | Lexical full-text baseline over CIE-10-ES descriptions. |
| ST MiniLM-L6-v2 | General-purpose public sentence-transformer baseline. |
| ST BioBERT | English biomedical sentence-transformer baseline. |
| ST MPNet-v2 | Larger 768-dimensional general sentence-transformer baseline. |
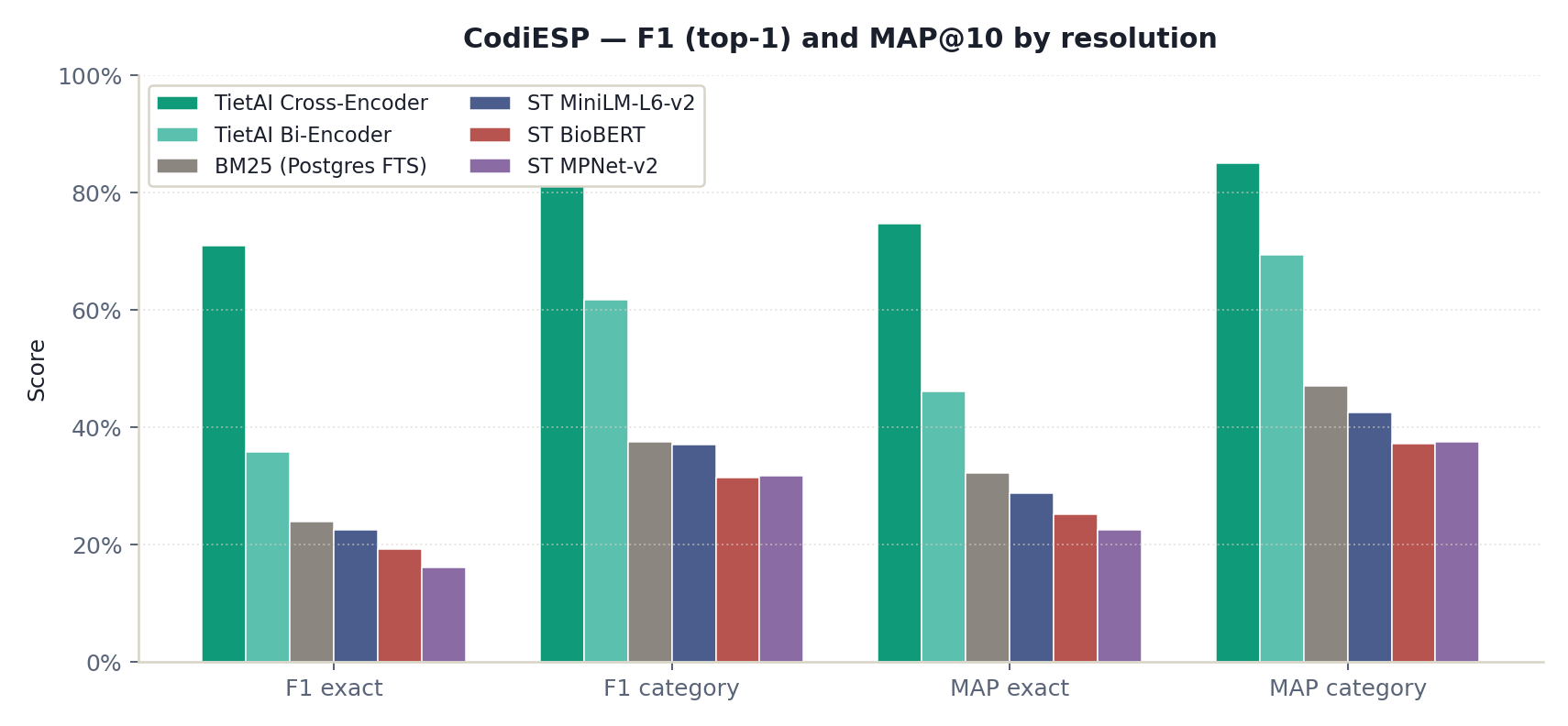
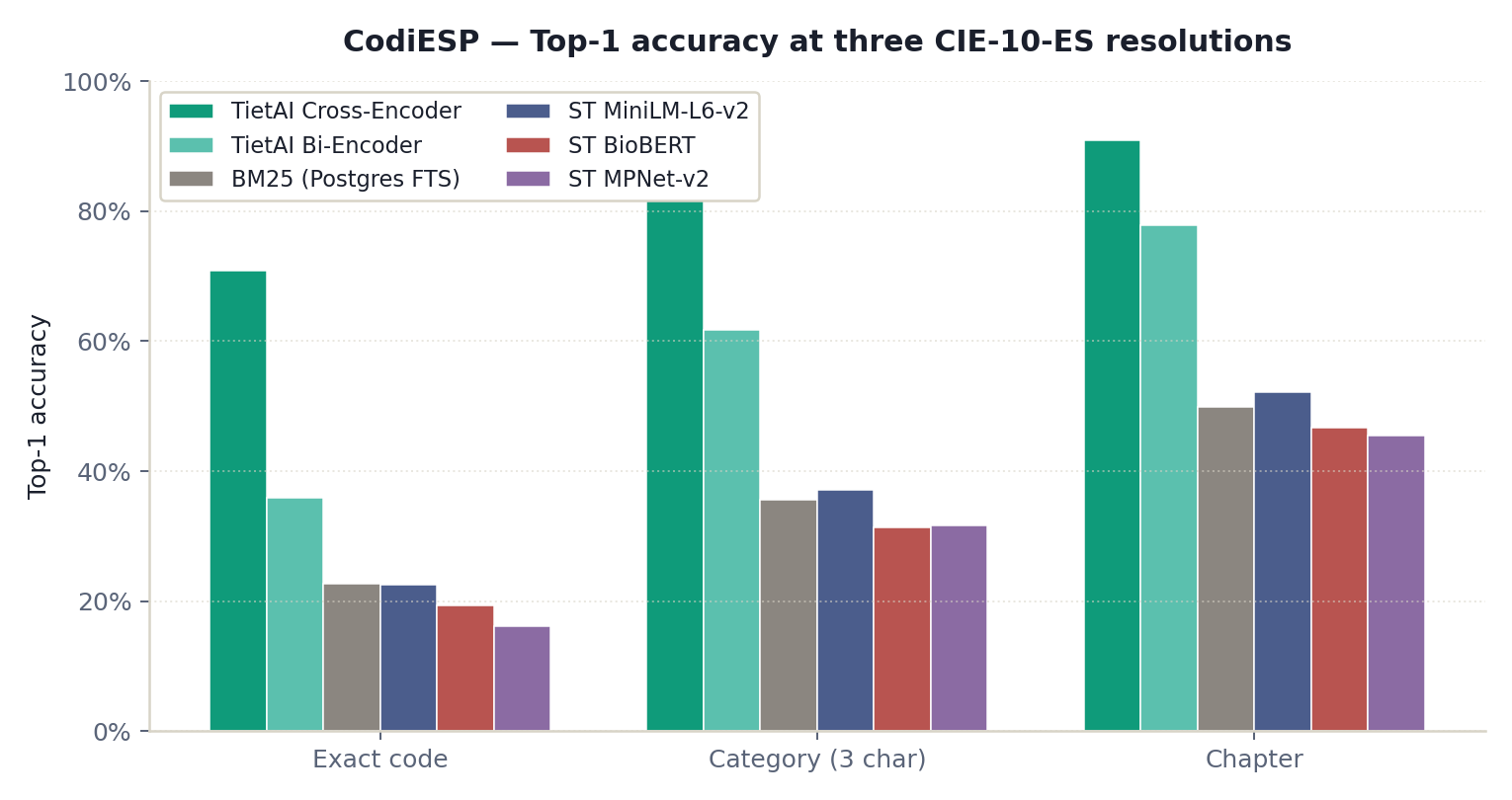
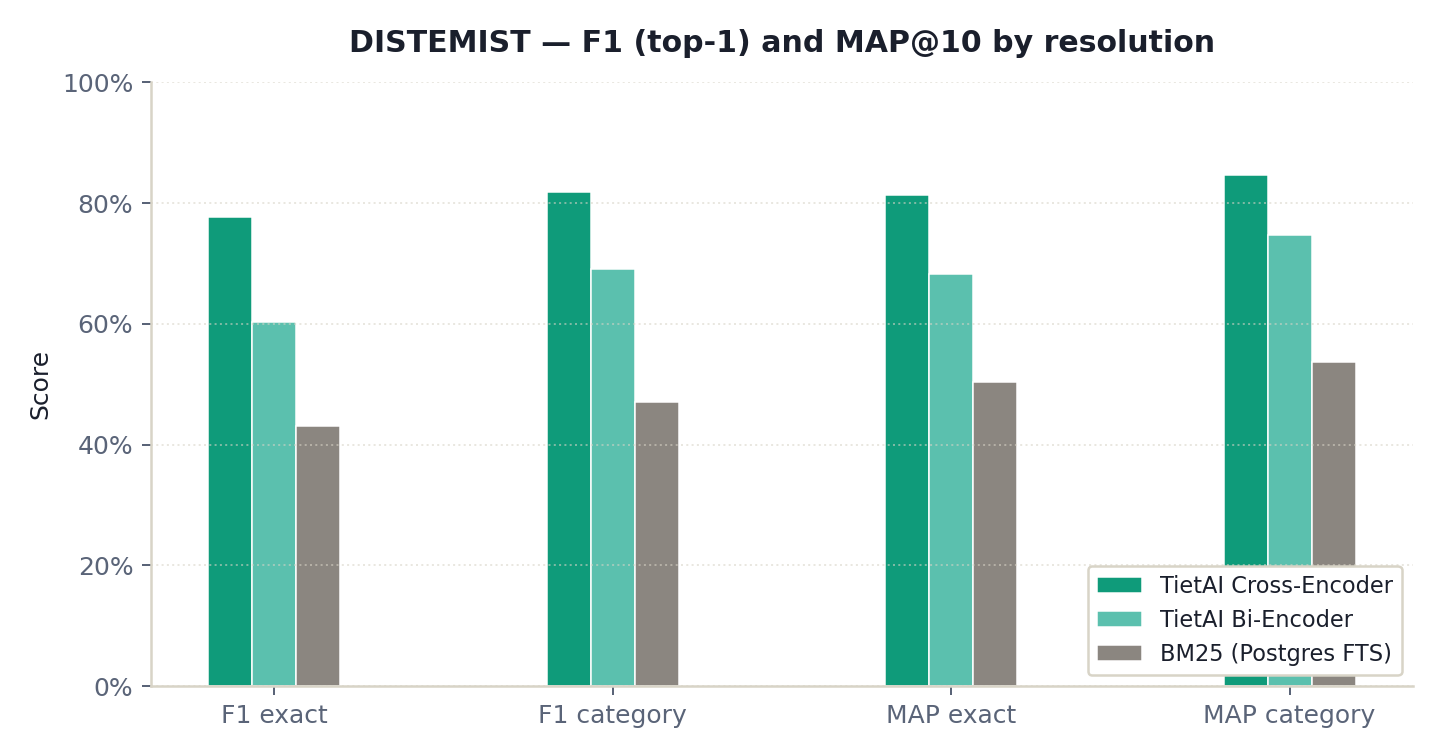
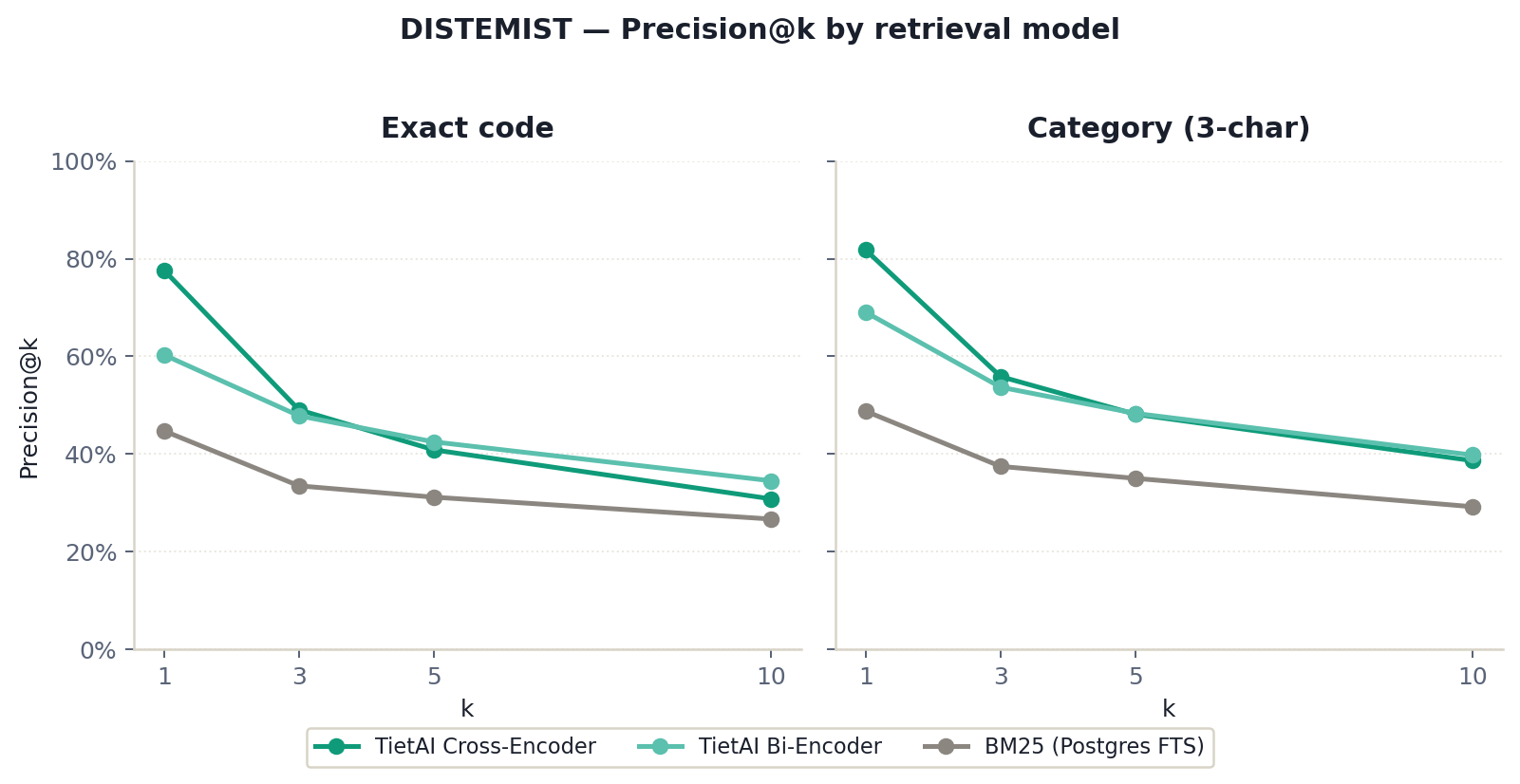
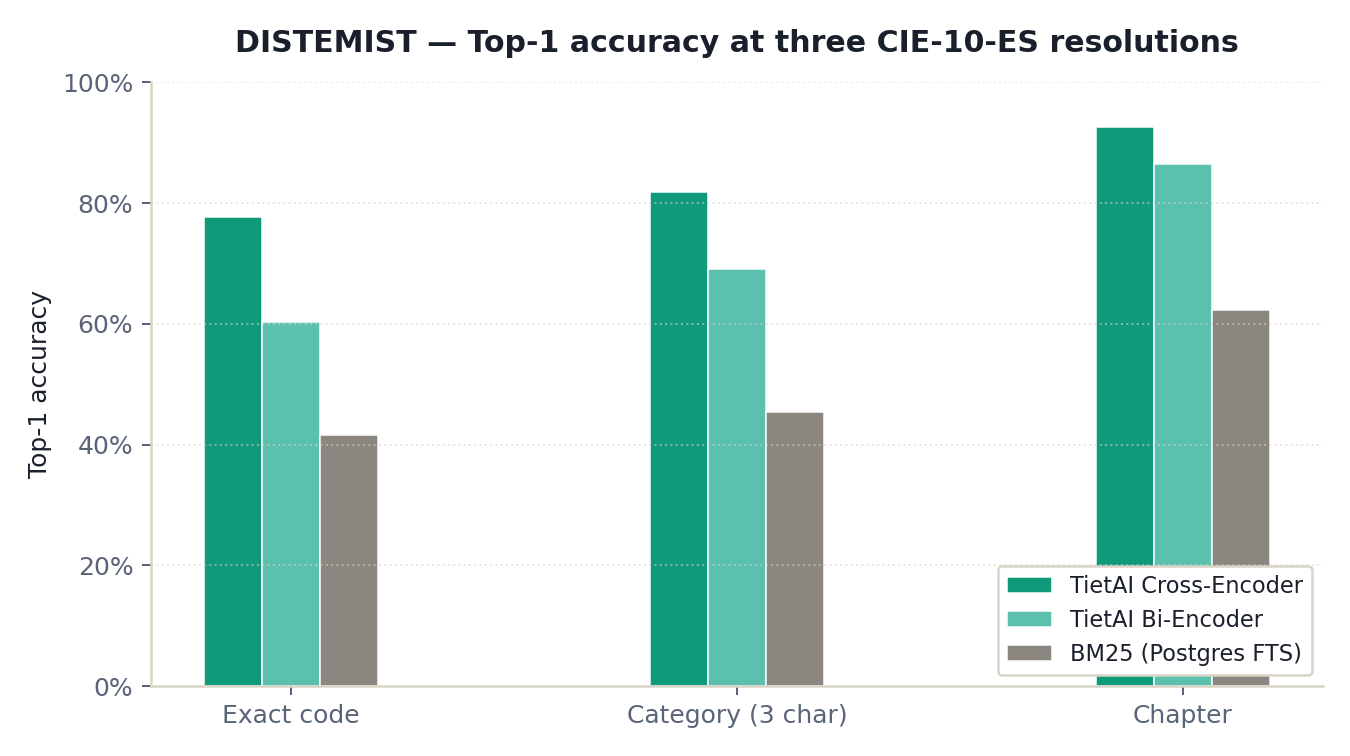
On CodiESP v4, the TietAI cross-encoder reaches F1 = 0.709 and MAP@10 = 0.747 at exact-code resolution. On DISTEMIST, it reaches F1 = 0.776 and MAP@10 = 0.812. The updated paper treats MAP@10 as the ranking metric and F1 as the top-1 decision metric.
| Model | F1 exact | F1 category | MAP@10 exact | MAP@10 category |
|---|---|---|---|---|
| TietAI Cross-Encoder | 0.709 | 0.823 | 0.747 | 0.851 |
| TietAI Bi-Encoder | 0.359 | 0.617 | 0.461 | 0.694 |
| BM25 (Postgres FTS) | 0.239 | 0.376 | 0.322 | 0.471 |
| ST MiniLM-L6-v2 | 0.225 | 0.371 | 0.287 | 0.426 |
| ST BioBERT | 0.193 | 0.314 | 0.252 | 0.373 |
| ST MPNet-v2 | 0.161 | 0.317 | 0.226 | 0.376 |
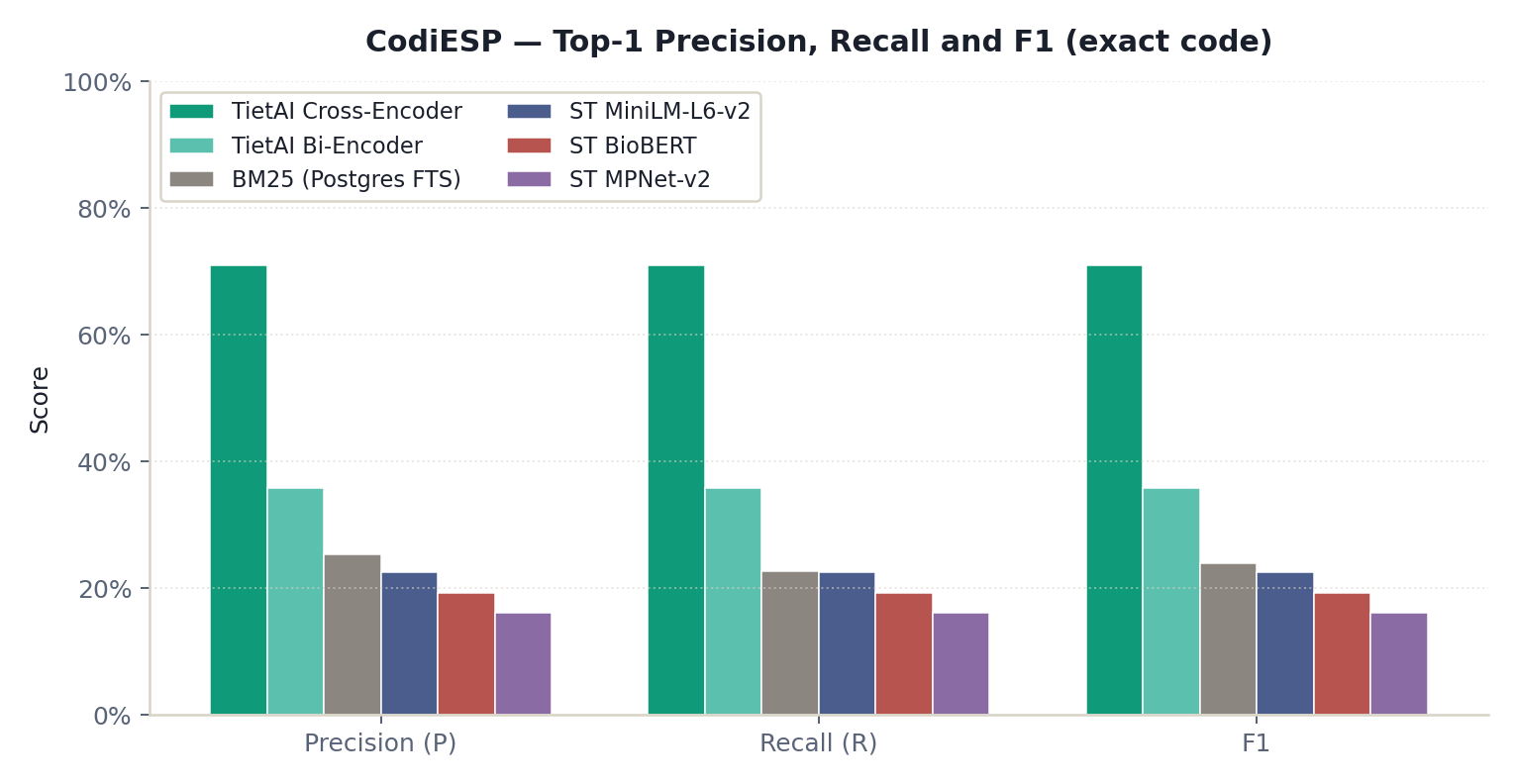
| Model | Precision | Recall | F1 |
|---|---|---|---|
| TietAI Cross-Encoder | 0.709 | 0.709 | 0.709 |
| TietAI Bi-Encoder | 0.359 | 0.359 | 0.359 |
| BM25 (Postgres FTS) | 0.254 | 0.227 | 0.239 |
| ST MiniLM-L6-v2 | 0.225 | 0.225 | 0.225 |
| ST BioBERT | 0.193 | 0.193 | 0.193 |
| ST MPNet-v2 | 0.161 | 0.161 | 0.161 |
| Model | F1 exact | F1 category | MAP@10 exact | MAP@10 category |
|---|---|---|---|---|
| TietAI Cross-Encoder | 0.776 | 0.818 | 0.812 | 0.846 |
| TietAI Bi-Encoder | 0.603 | 0.690 | 0.682 | 0.747 |
| BM25 (Postgres FTS) | 0.431 | 0.470 | 0.504 | 0.537 |
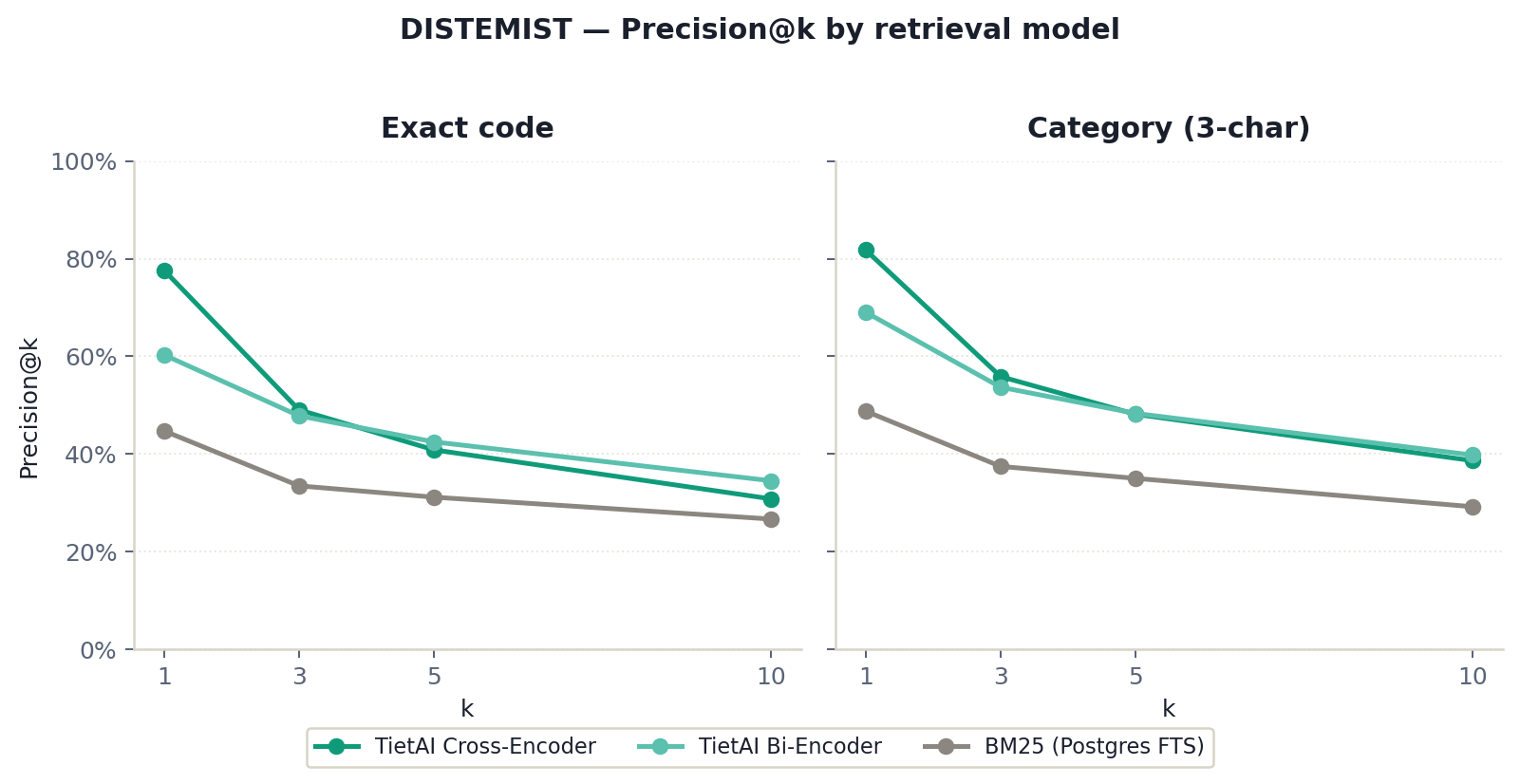
The public-baseline ordering is the important negative result. BioBERT-ST has biomedical pretraining, but it is English-centric. MPNet-v2 has larger embeddings, but it still trails MiniLM-L6-v2. Neither scale nor generic domain pretraining solves Spanish clinical-code retrieval by itself.
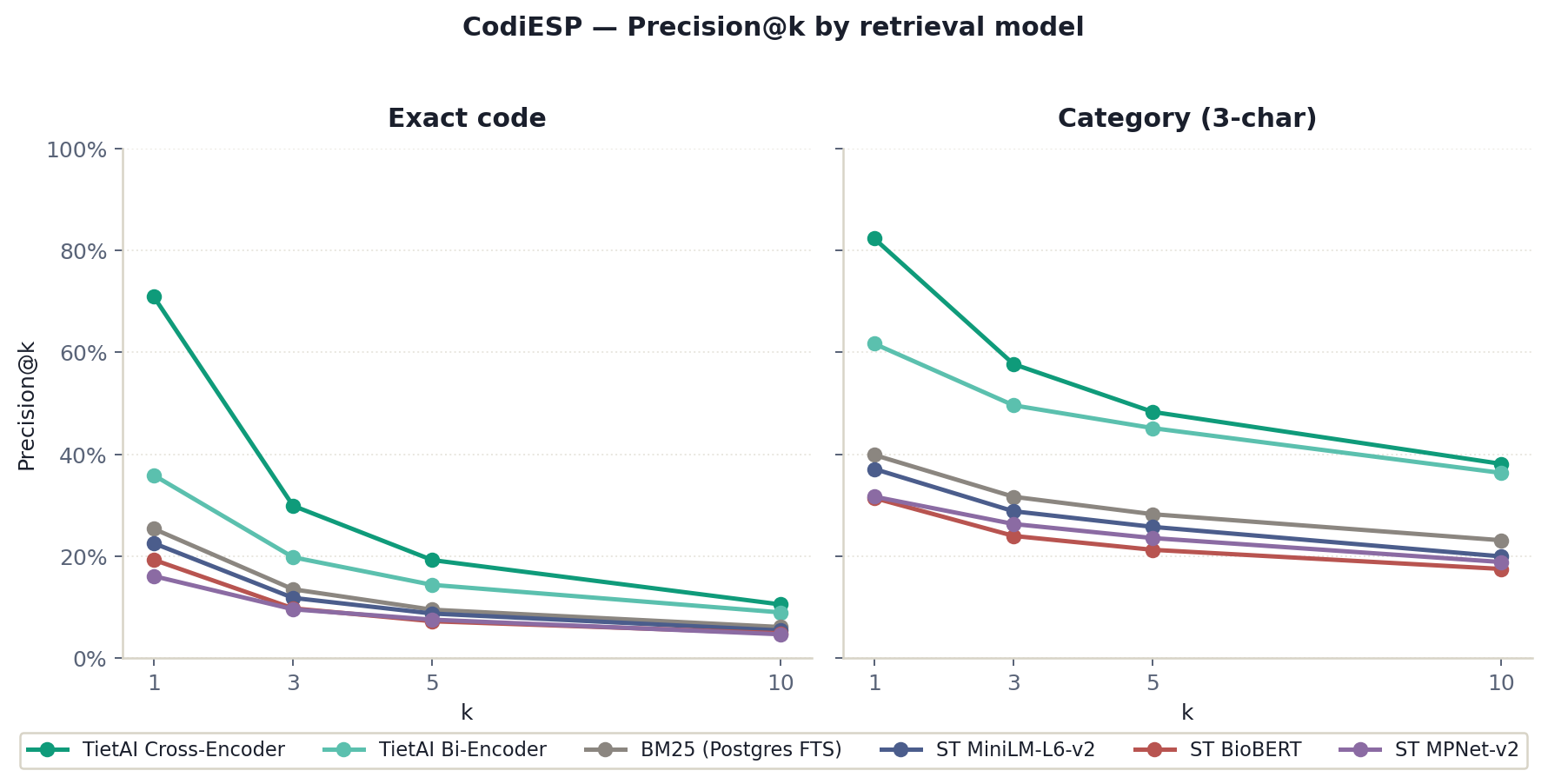
ICD retrieval requires models to separate sibling concepts that are semantically close but operationally different. The bi-encoder captures chapter-level topic information well, but exact-code ranking needs a reranker trained on hard negatives drawn from neighboring CIE-10 codes.