PySynthea is a Python-native reimplementation of Synthea, designed to make synthetic longitudinal EHR generation installable, extensible, reproducible, and usable directly inside the data science stack where modern healthcare AI work already happens.
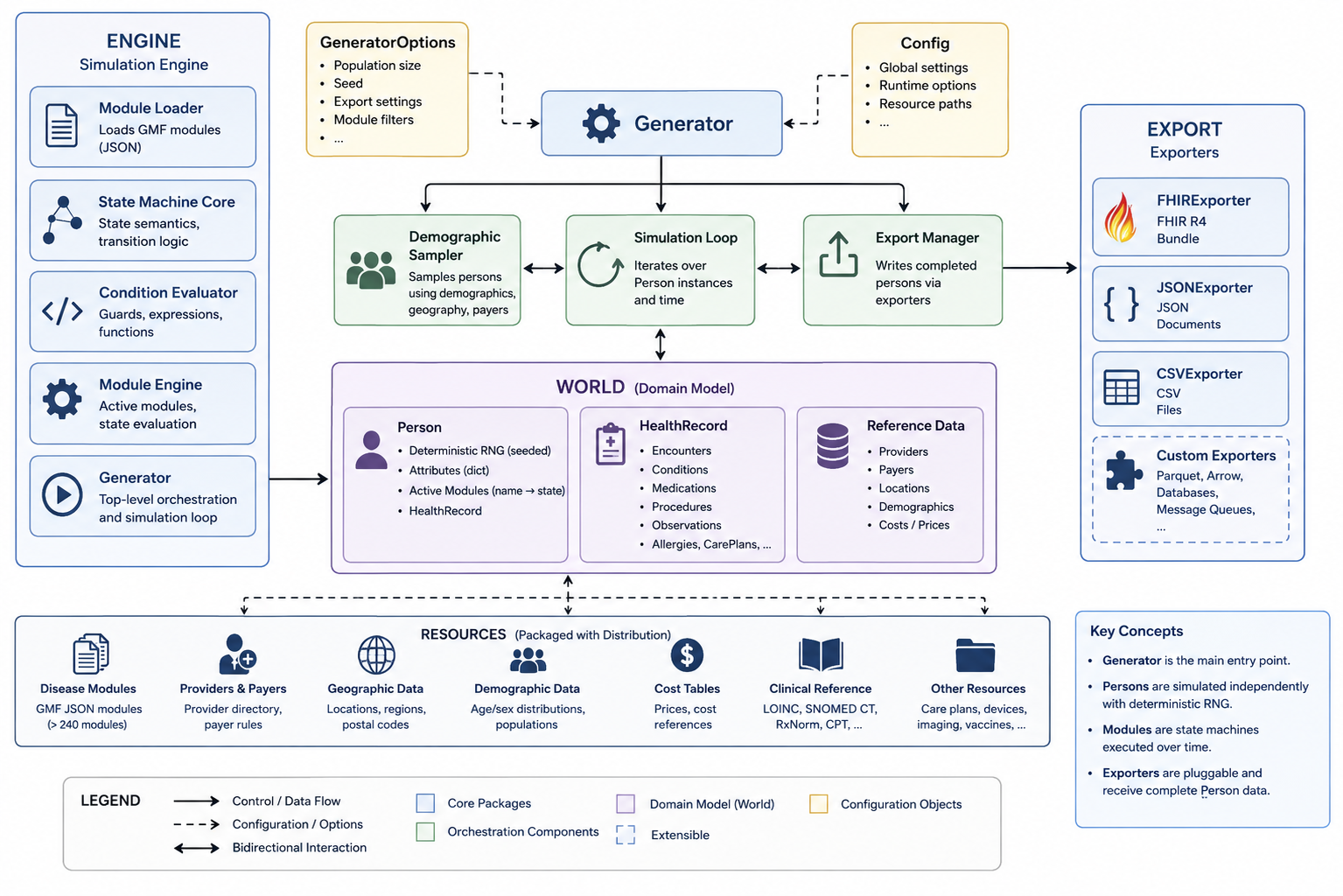
System architecture. PySynthea organizes synthetic patient generation around a Python Generator, deterministic Person instances, a GMF-compatible module engine, and export layers for FHIR, JSON, CSV, and analytics-friendly formats.
Synthetic healthcare data lets teams prototype, teach, test, and benchmark without exposing protected health information. Synthea made this practical for longitudinal EHR data, but many researchers now work almost entirely in Python, pandas, Jupyter, PyTorch, Dask, and PySpark.
PySynthea keeps the core Synthea model: modular disease state machines, demographic population sampling, longitudinal patient histories, and standards-conformant export. The difference is operational. It is designed to install with standard Python tooling, run without a JVM, expose a clean Python API, and put generated records directly into the workflows used for healthcare data science and applied AI.
Real EHR data is constrained by HIPAA, GDPR, institutional review, contractual restrictions, and re-identification risk. Synthetic data does not replace real clinical validation, but it gives teams a shareable, reproducible substrate for early experimentation and engineering.
| Goal | What it means |
|---|---|
| Accessibility | Python-native install and use, with no external JVM runtime. |
| Interoperability | Natural integration with pandas, NumPy, PyTorch, Dask, PySpark, Airflow, and Jupyter. |
| Reproducibility | Deterministic generation from explicit seeds and configuration. |
| Extensibility | Documented extension points for state types, exporters, modules, and simulation behavior. |
| Scalability | Interactive notebook cohorts and larger parallel batch jobs share the same API. |
| Standards fidelity | FHIR R4, CSV, JSON, and Synthea-compatible identifiers remain first-class outputs. |
PySynthea is organized as a single Python distribution with four primary packages: the simulation engine, the healthcare world model, export adapters, and helper utilities for configuration and shared behavior.
The Generator coordinates demographic sampling, simulation, module execution, and export. Each Person carries deterministic randomness, attributes, active module state, and a HealthRecord. Modules are loaded from Synthea GMF JSON and executed as typed state machines, including encounters, condition onsets, medication orders, observations, procedures, care plans, devices, diagnostic reports, immunizations, and terminal states.
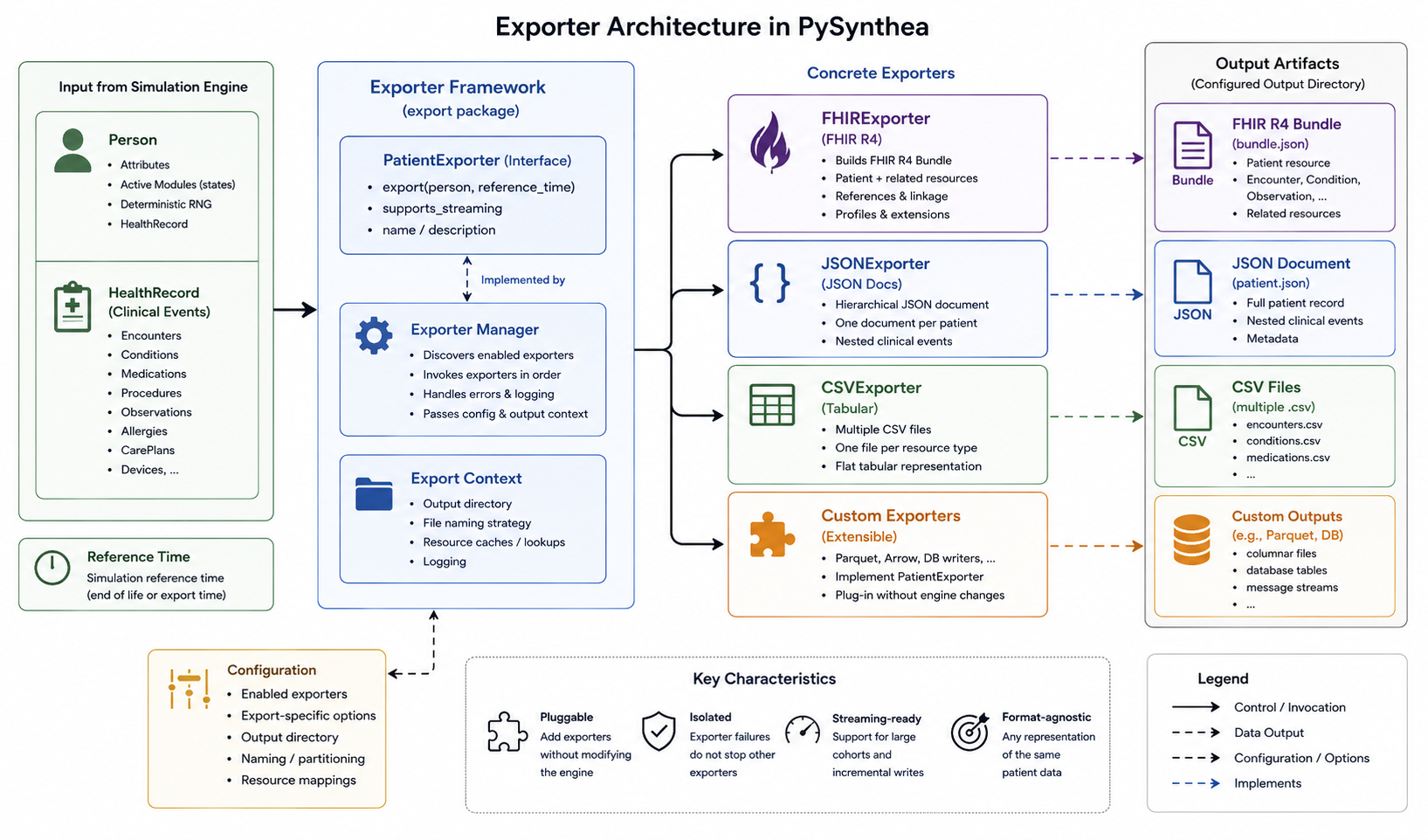
Because generation runs in-process, records can be inspected immediately as Python objects, materialized as DataFrames, converted to model-ready sequences, written to a FHIR server, or partitioned for distributed jobs.
| Format | Primary use |
|---|---|
| FHIR R4 | FHIR server loading, validation, interoperability testing, and SMART-on-FHIR development. |
| CSV | Flat resource tables for pandas, spreadsheets, and database bulk loading. |
| JSON | Nested patient documents for debugging, document databases, and complete history inspection. |
| Parquet | Columnar analytics for data lakes, PySpark, Dask, and lakehouse workflows. |
| Relational DB | Research warehouses, test databases, and downstream schema mappings through SQLAlchemy or pandas. |
PySynthea is an independent engine, so exact semantic parity with upstream Java Synthea remains a continuing validation target. The goal is to keep Synthea GMF modules as the shared clinical content source while making the engine easier for Python users to extend, profile, test, and embed.
The paper also makes a clear distinction between Synthea-style synthetic data and learned generative models. PySynthea is valuable for structural, longitudinal, standards-conformant records, education, reproducibility, and pipeline testing. It is not a substitute for clinical validation on real cohorts or a learned model that reproduces the distribution of a specific institution.