01
EHDS-Frist 2027
Die EHDS-Verordnung verpflichtet Mitgliedstaaten und Gesundheitsorganisationen bis 2027 zur kontrollierten Sekundärnutzung von Gesundheitsdaten mit vollständiger Auditierbarkeit und Governance.
EHDS · OMOP · Geregelter Datenaustausch
Hydra hilft Gesundheitsorganisationen, interoperable Datensätze für die Sekundärnutzung zu entwerfen, zu steuern, zu anonymisieren, zu transformieren und zu veröffentlichen.
Die Plattform kombiniert HealthDCAT-AP-Kataloge, IDS/Gaia-X-Muster, OMOP-Modellierung und agentengestützte Abläufe, damit Datenassets vom Inventar bis zum kontrollierten Zugriff gelangen.
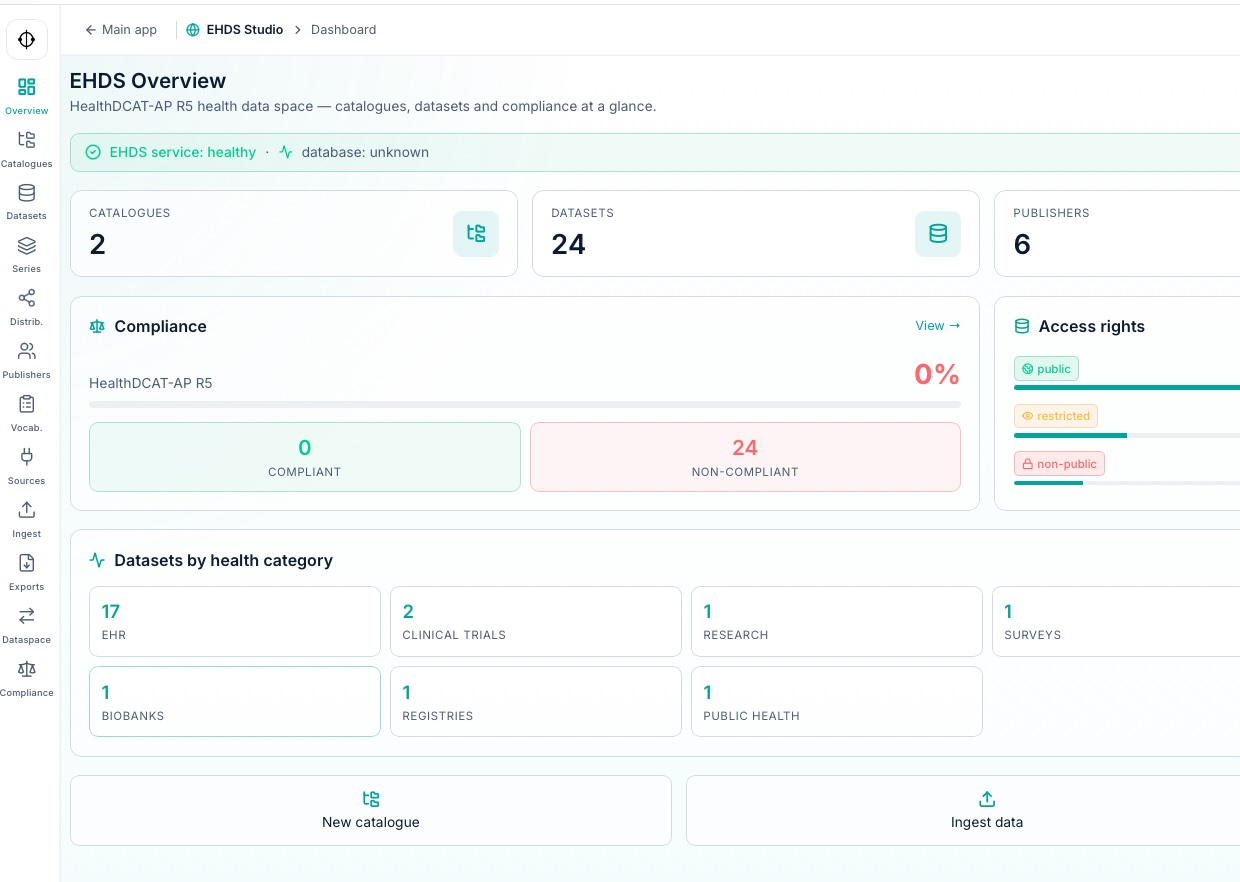
HealthDCAT-AP
Metadatenkataloge bereit für europäische Föderation
8 Konnektoren
TCP/MLLP, HTTP, Dateien, Datenbanken, SMTP, WebSocket und Kafka
18 PHI
automatische Anonymisierung mit Auditierbarkeit
OMOP CDM
forschungsnahe Modellierung und Terminologieabgleich
Die EHDS-Verordnung verpflichtet Mitgliedstaaten und Gesundheitsorganisationen bis 2027 zur kontrollierten Sekundärnutzung von Gesundheitsdaten mit vollständiger Auditierbarkeit und Governance.
Patientenakten, Kohortendatensätze und Forschungsergebnisse sind auf Krankenhäuser, Register und Netzwerke verteilt — ohne eine regulierte Austauschschicht nicht zugänglich.
Die meisten Teams wenden De-Identifizierung und Katalogisierung manuell an — ohne Standardformat, ohne Prüfpfad und ohne Ausrichtung auf HealthDCAT-AP oder OMOP für den föderativen Zugriff.
Föderierte Kohortenstudien, Real-World-Evidence und Registryabfragen erfordern terminologisch ausgerichtete, OMOP-bereite Datensätze — ohne gemeinsames Modell bleibt die institutionsübergreifende Forschung manuell und fehleranfällig.
Plattformarchitektur
Eine einzige Plattform deckt den gesamten Weg ab: Katalog, Ingestion, Anonymisierung, OMOP-Modellierung und regulierte Verteilung an die europäische Gesundheitsdateninfrastruktur.
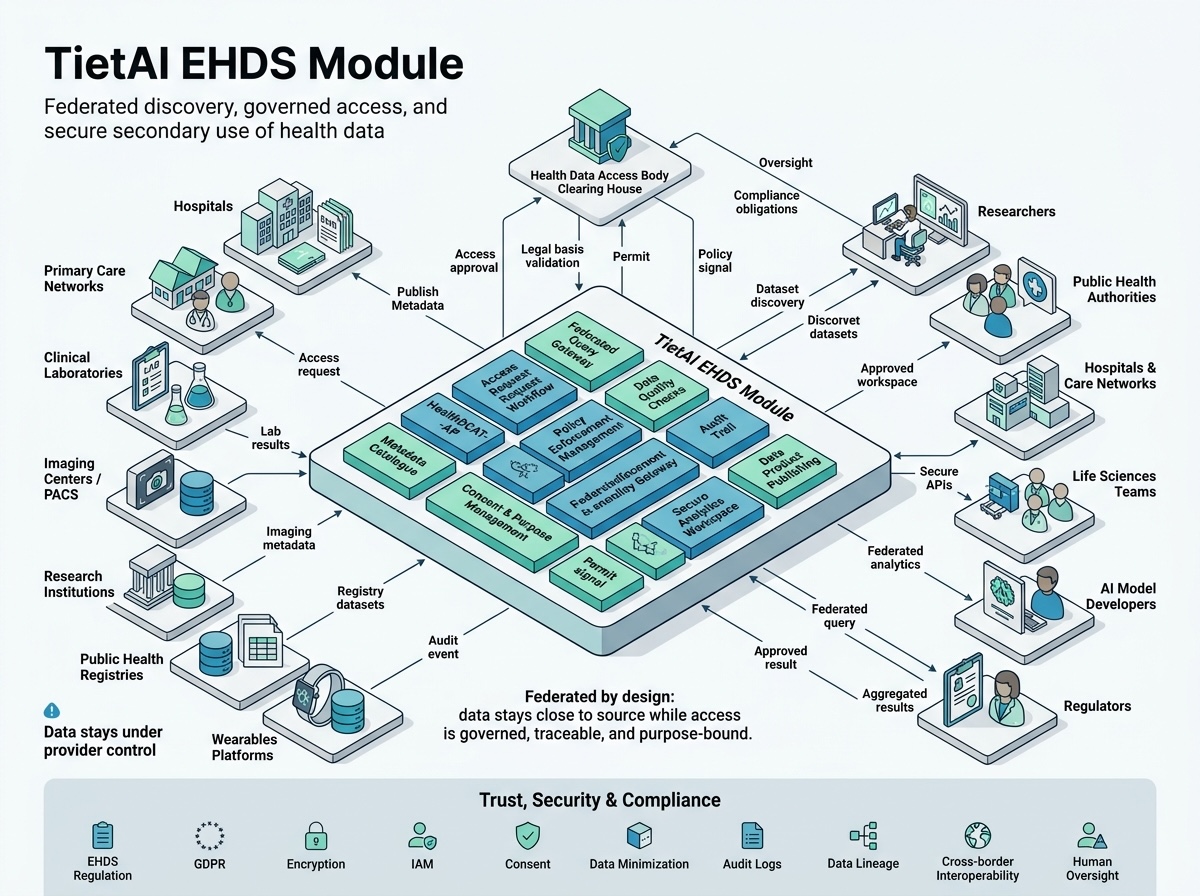
Die EHDS-Schicht fokussiert Katalogisierung, Interoperabilität, Anonymisierung, Verteilung und richtlinienbasierten Austausch in Versorgungs- und Forschungsnetzwerken.
Erstellen Sie standardisierte Metadaten für Datensätze und Datendienste, einschließlich RDF-Export für künftige europäische Gesundheitsdatenföderation.
Verbinden Sie FHIR, OLTP/OLAP, Dateien, Datenbanken, HTTP, TCP/MLLP, WebSocket, Kafka, SMTP und weitere operative Systeme.
Erkennen und behandeln Sie Identifikatoren in strukturierten und unstrukturierten Daten mit Schwärzung, Markern, Maskierung, Verschlüsselung und synthetischem Ersatz.
Veröffentlichen Sie herunterladbare Distributionen oder API-Zugriff über mehrere Ziele, Formate und Gesundheitsdatenkategorien hinweg.
Definieren Sie Assets, Richtlinien, Verträge, Verhandlungen und Transfermonitoring für interoperable Datenraumabläufe.
Beschleunigen Sie Katalogaufbau, Asset-Vorbereitung, Engineering-Workflows und operative Veröffentlichung mit geführten Agenten.
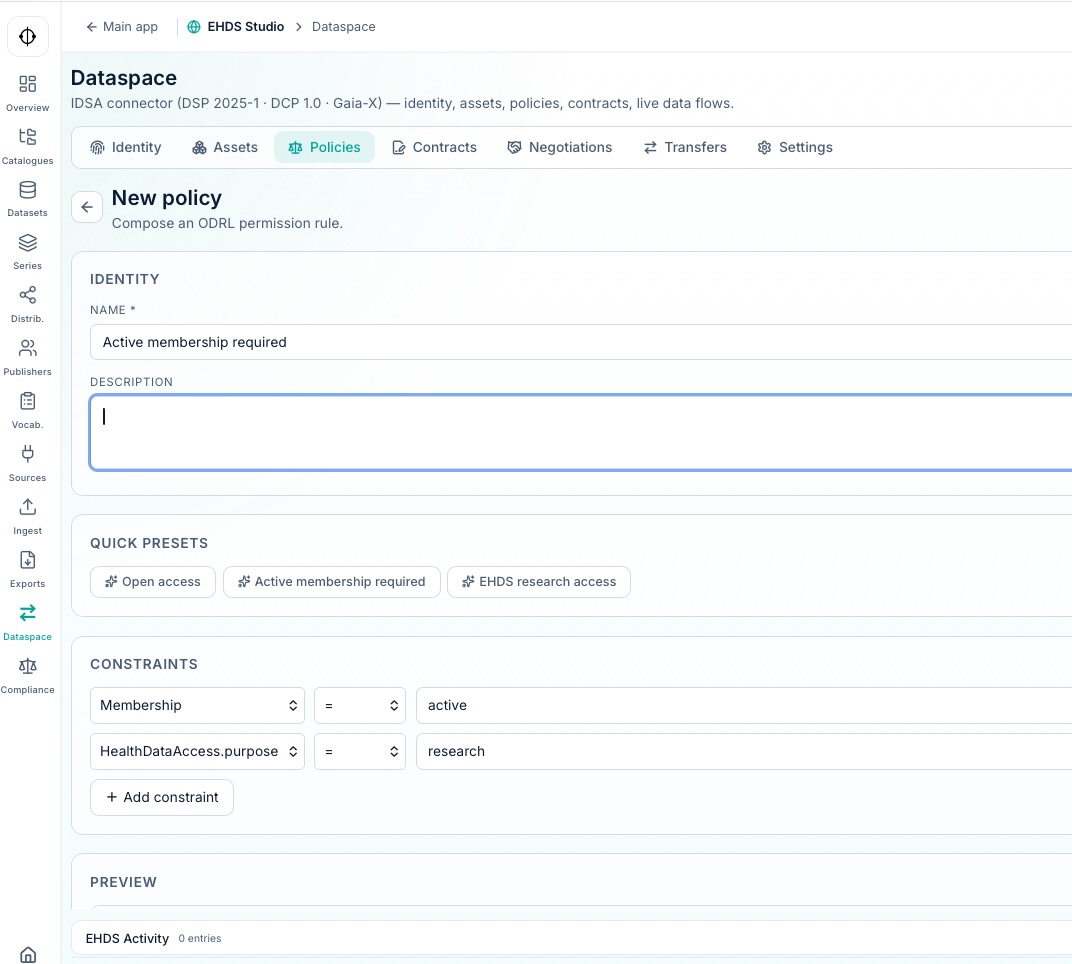
Regeln und Governance
Hydra erzeugt eine vollständige Governance-Schicht über alle Datensätze im Datenraum hinweg und folgt den TEHDAS2-Empfehlungen für Richtliniendefinition, Lebenszykluskontrolle, Auditierbarkeit und kontrollierte Sekundärnutzung.
Dieses Regelwerk kann über eine Reihe von Konnektoren veröffentlicht werden, die mit dem DSP-Protokoll und den IDSA-Empfehlungen kompatibel sind. Hydra implementiert außerdem die in TEHDAS2 M7.3 beschriebene National-Contact-Point-Architektur (NCP), basierend auf einem Zwei-Schichten-Modell: Business Layer (Dispatcher) und Messaging Layer (eDelivery/Domibus).
Die OMOP-Schicht unterstützt Modellierung, Terminologievalidierung, Dokumentation, Export und wissensbasierte Anreicherung für Forschung und Sekundärnutzung.
Mappen Sie Quelldatensätze in das OMOP Common Data Model mit wiederholbaren Workflows für Ingestion, Transformation und Validierung.
Validieren Sie ICD-10, ICD-11, SNOMED CT, LOINC, ATC, ICPC-2, HPO, OMOP CDM und mit UMLS verknüpfte Konzepte.
Erzeugen Sie Prüfungen, Transformationsdokumentation und kontrollierte Exporte, damit Datensätze nachvollziehbar und wiederverwendbar bleiben.
Nutzen Sie Modelle für natürliche Sprachverarbeitung, um klinische Entitäten in Texten zu erkennen und strukturierte Modellierungspipelines zu speisen.
Nutzen Sie graphbasierte Terminologiedienste, Ontologienavigation, semantische Suche und agentenfreundliche APIs für Konzeptabgleich.
Erzeugen Sie interoperable Datendienste und Datensatzdistributionen für Forschung, Analytik, KI-Agenten und regulierten Austausch.
Beginnen Sie mit Katalogmanagement und Dateninventar, gehen Sie zu Ingestion und Transformation über und veröffentlichen Sie kontrollierte Distributionen als Download oder API.
Governance, Anonymisierung, Terminologievalidierung und Richtlinienhandling bleiben mit dem Lebenszyklus des Datensatzes verbunden, statt manuelle Nebenarbeit zu werden.
Bauen Sie die Katalog-, Governance-, OMOP-Modellierungs- und Verteilungsschicht für Sekundärnutzung und europäische Gesundheitsdatenkooperation.