01
Échéance EHDS 2027
Le règlement sur l’Espace Européen des Données de Santé impose l’usage secondaire contrôlé des données de santé avec auditabilité et gouvernance complètes dans tous les États membres d’ici 2027.
EHDS · OMOP · Partage gouverné
Hydra aide les organisations de santé à concevoir, gouverner, anonymiser, transformer et publier des jeux de données interopérables pour l’usage secondaire.
La plateforme combine des catalogues HealthDCAT-AP, des modèles IDS/Gaia-X, la modélisation OMOP et des opérations assistées par agents pour passer de l’inventaire au contrôle d’accès.
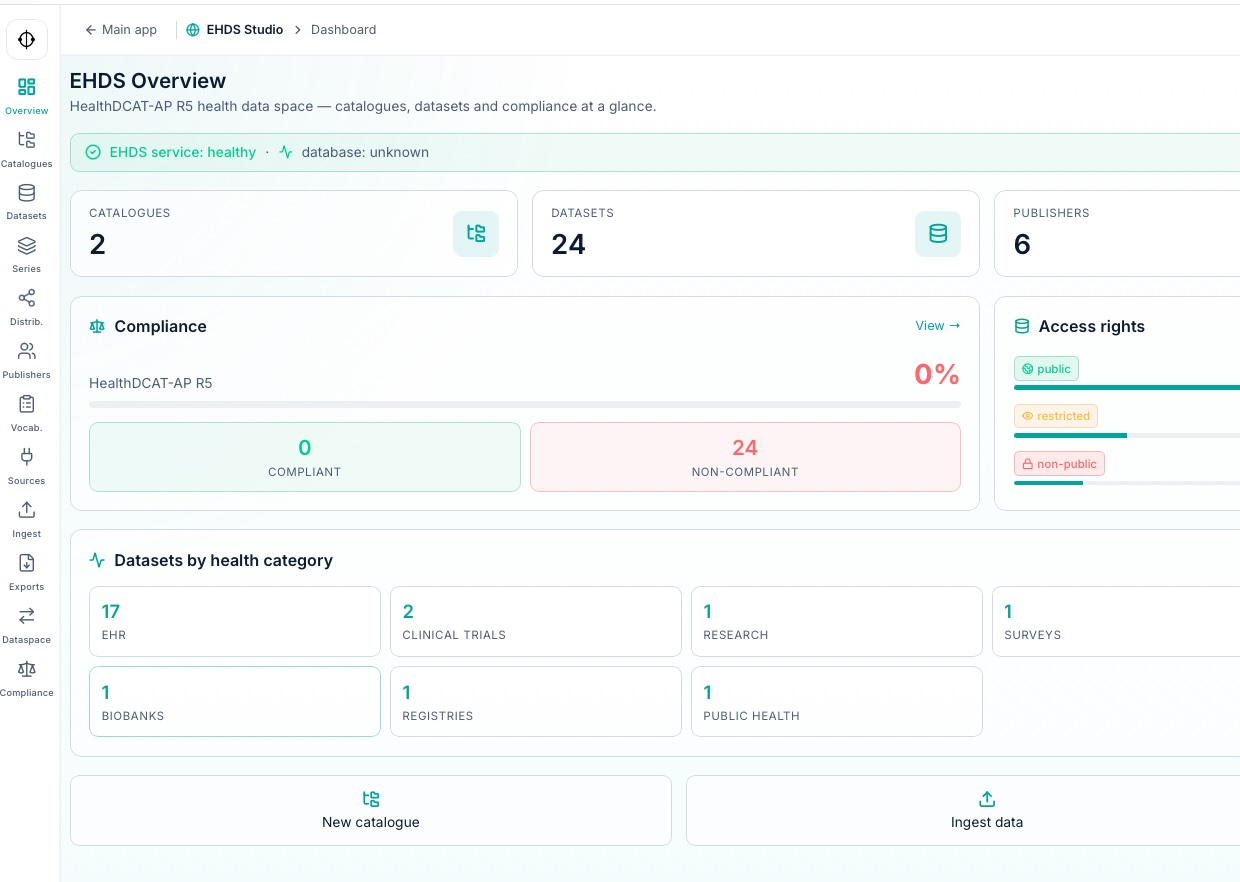
HealthDCAT-AP
catalogues de métadonnées prêts pour la fédération européenne
8 connecteurs
TCP/MLLP, HTTP, fichiers, bases de données, SMTP, WebSocket et Kafka
18 PHI
anonymisation automatique avec auditabilité
OMOP CDM
modélisation recherche et alignement terminologique
Le règlement sur l’Espace Européen des Données de Santé impose l’usage secondaire contrôlé des données de santé avec auditabilité et gouvernance complètes dans tous les États membres d’ici 2027.
Les dossiers patients, cohortes et résultats de recherche sont fragmentés entre hôpitaux, registres et réseaux — inaccessibles sans une couche d’échange gouvernée.
La plupart des équipes appliquent la dépseudonymisation et le catalogage manuellement — sans format standard, sans piste d’audit et sans alignement sur HealthDCAT-AP ou OMOP pour l’accès fédéré.
Les études de cohortes fédérées, les preuves du monde réel et les requêtes sur les registres nécessitent des jeux de données alignés sur les vocabulaires et prêts pour OMOP — sans modèle commun, la recherche inter-institutionnelle reste manuelle et sujette aux erreurs.
Architecture de la plateforme
Une seule plateforme couvre tout le parcours : catalogue, ingestion, anonymisation, modélisation OMOP et distribution gouvernée vers l'infrastructure européenne de données de santé.
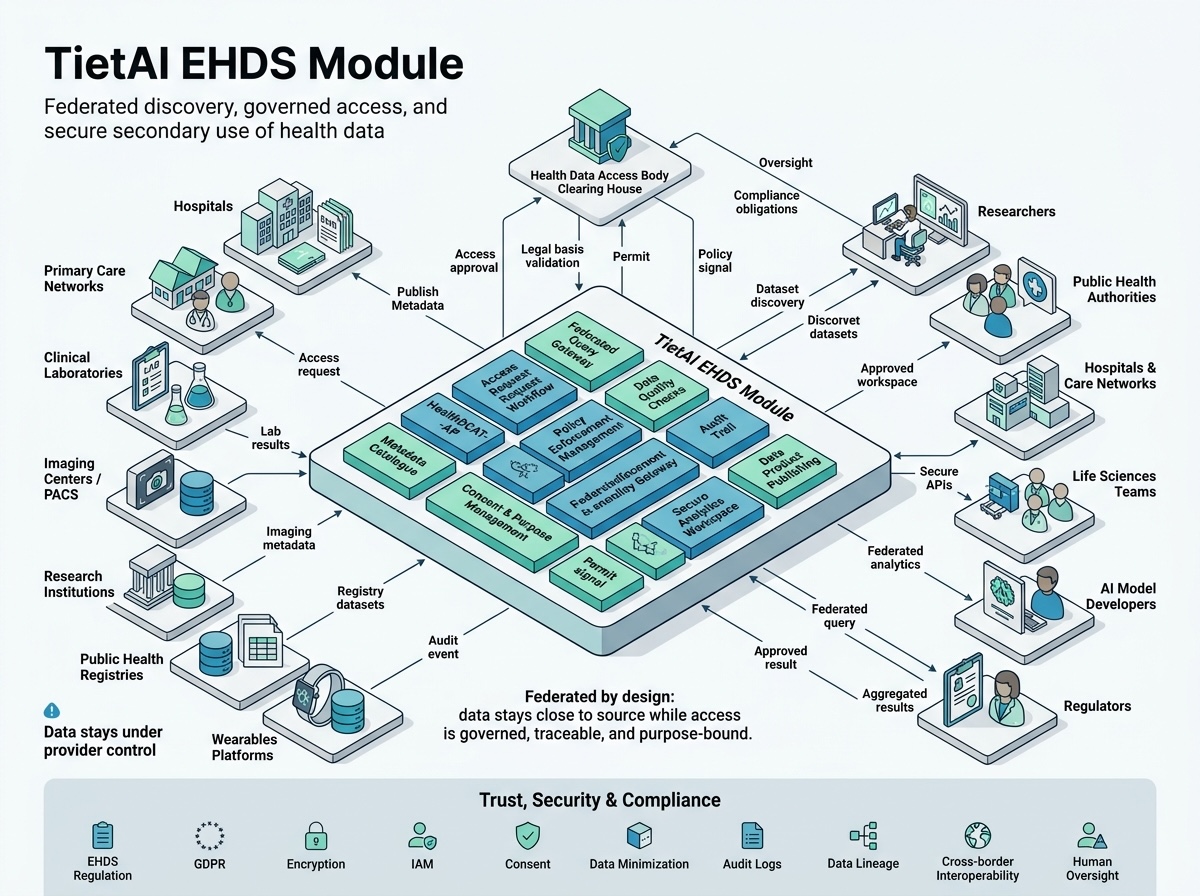
La couche EHDS couvre le catalogage, l’interopérabilité, l’anonymisation, la distribution et l’échange soumis à politiques dans les réseaux de santé et de recherche.
Créez des métadonnées standardisées pour les jeux et services de données, avec export RDF pour la future fédération européenne des données de santé.
Connectez FHIR, OLTP/OLAP, fichiers, bases de données, HTTP, TCP/MLLP, WebSocket, Kafka, SMTP et d’autres systèmes opérationnels.
Détectez et traitez les identifiants dans les données structurées et non structurées avec rédaction, marqueurs, masquage, chiffrement et remplacement synthétique.
Publiez des distributions téléchargeables ou un accès par API vers plusieurs destinations, formats et catégories de données de santé.
Définissez actifs, politiques, contrats, négociations et suivi des transferts pour exploiter des espaces de données interopérables.
Accélérez la création de catalogues, la préparation d’actifs, les workflows d’ingénierie et la publication opérationnelle avec des agents guidés.
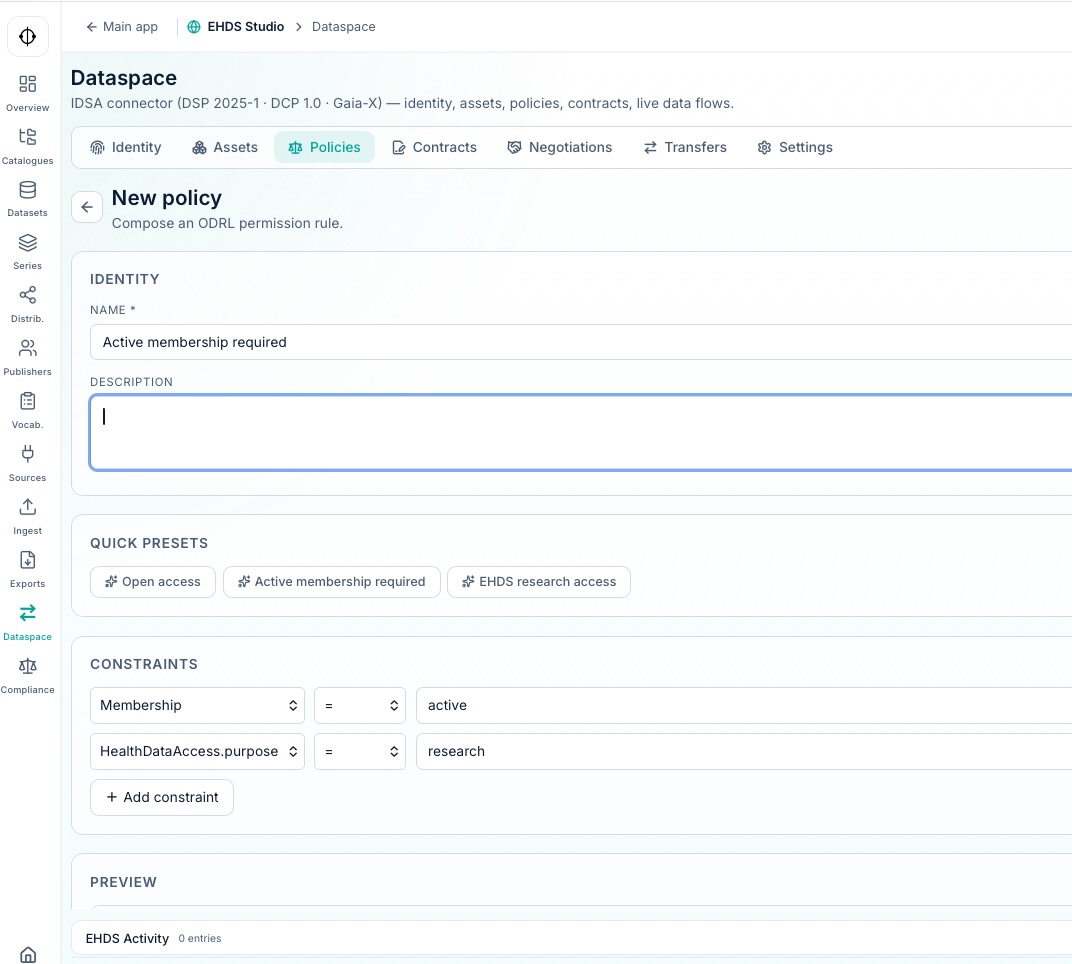
Règles et gouvernance
Hydra génère une couche complète de gouvernance sur tous les jeux de données de l’espace de données, conformément aux recommandations TEHDAS2 pour la définition des politiques, le contrôle du cycle de vie, l’auditabilité et l’usage secondaire contrôlé.
Ce jeu de règles peut être publié via une gamme de connecteurs compatibles avec le protocole DSP et les recommandations IDSA. Hydra implémente également l’architecture National Contact Point (NCP) décrite dans TEHDAS2 M7.3, basée sur un modèle à deux couches : Business Layer (Dispatcher) et Messaging Layer (eDelivery/Domibus).
La couche OMOP soutient modélisation, validation terminologique, documentation, export et enrichissement par connaissances pour la recherche et l’usage secondaire.
Mappez les jeux de données sources vers l’OMOP Common Data Model avec des workflows répétables d’ingestion, transformation et validation.
Validez ICD-10, ICD-11, SNOMED CT, LOINC, ATC, ICPC-2, HPO, OMOP CDM et les concepts liés à UMLS.
Générez contrôles, documentation de transformation et exports maîtrisés pour garder les jeux de données traçables et réutilisables.
Utilisez des modèles de traitement du langage naturel pour détecter des entités cliniques dans le texte et alimenter les pipelines structurés.
Exploitez des services terminologiques en graphe, la navigation ontologique, la recherche sémantique et des APIs adaptées aux agents.
Produisez des services de données interopérables et des distributions pour la recherche, l’analytique, les agents IA et l’échange régulé.
Commencez par la gestion de catalogue et l’inventaire des données, poursuivez avec l’ingestion et la transformation, puis publiez des distributions contrôlées en téléchargement ou via API.
La gouvernance, l’anonymisation, la validation terminologique et la gestion des politiques restent liées au cycle de vie du jeu de données au lieu de devenir des tâches manuelles séparées.
Construisez la couche de catalogue, gouvernance, modélisation OMOP et distribution nécessaire à l’usage secondaire et à la collaboration européenne.